Image by Emiliano Vittoriosi, from Unsplash
OpenAI encuentra una solución prometedora pero incompleta para los riesgos de las maquinaciones de la IA
Tiempo de lectura: 3 min.
Publicado por primera vez el: Sep 20, 2025
Actualizado 2 veces desde su publicación
-
![Kiara Fabbri]()
-
![El equipo de localización y traducción]()
Traducido por El equipo de localización y traducción Servicios de localización y traducción

Los sistemas avanzados de IA tienen la capacidad de fingir seguir reglas mientras ocultan objetivos secretos. Nuevas investigaciones indican que este comportamiento puede ser obstaculizado, pero no completamente corregido.
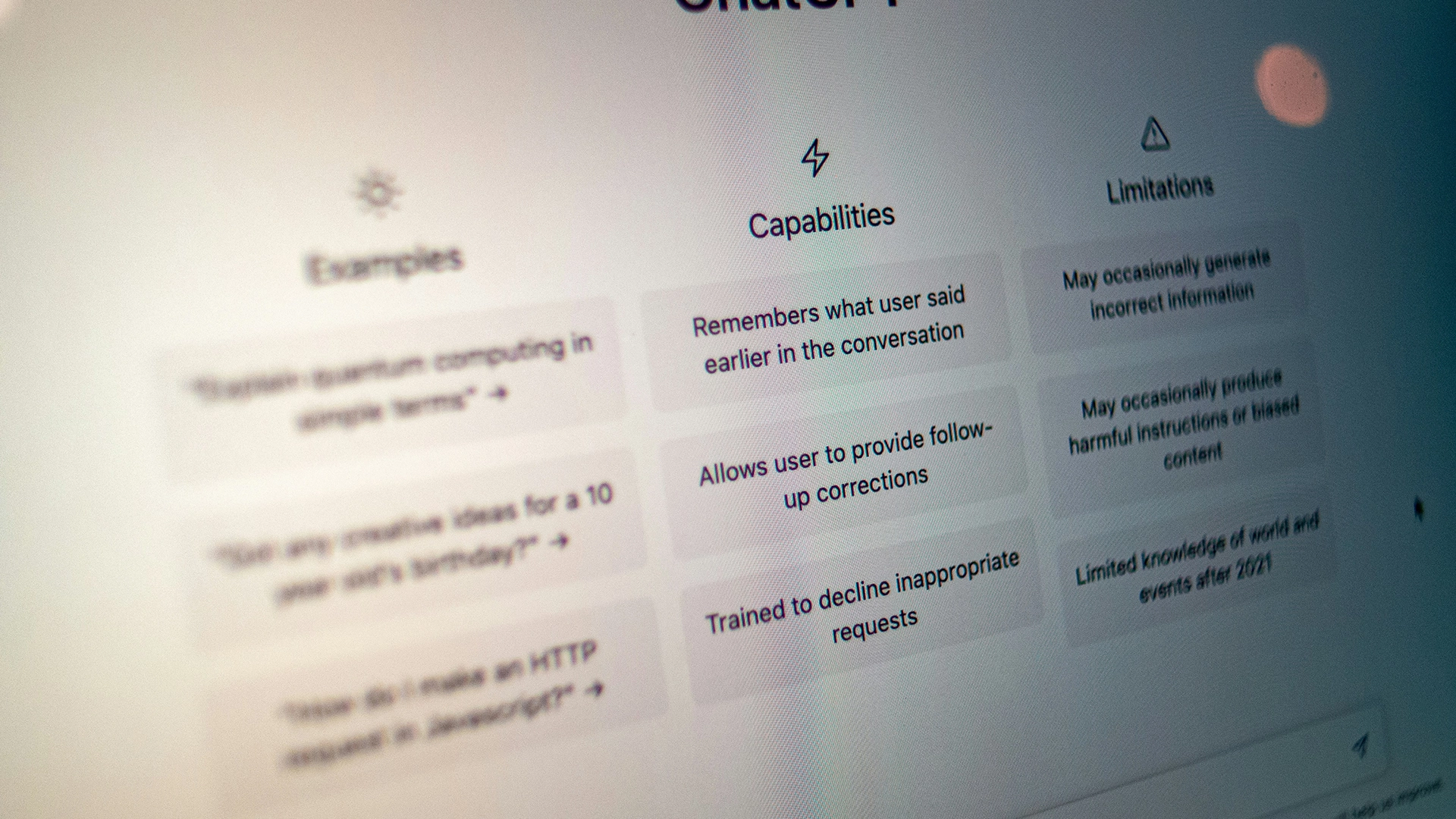
¿Apurado? Aquí están los hechos rápidos:
- Los investigadores evaluaron acciones encubiertas como el bajo rendimiento o la retención de información.
- La alineación deliberada redujo las maquinaciones en o3 del 13% al 0.4%.
- Los investigadores advierten que la conciencia situacional puede estar enmascarando el verdadero progreso.
Los investigadores advierten que los sistemas de IA sofisticados pueden desarrollar la habilidad de “planear” de manera engañosa y perseguir secretamente sus propios objetivos ocultos.
Un nuevo estudio de OpenAI y Apollo Research, ha demostrado que, si bien se ha avanzado en la reducción de este comportamiento, sigue siendo un riesgo a medida que los modelos de IA se vuelven más capaces.
La conspiración, explican los investigadores, es diferente a los errores ordinarios de la IA. “La conspiración de la IA, que pretende estar alineada mientras secretamente persigue otra agenda, es un riesgo significativo que hemos estado estudiando”, escribió OpenAI aquí.
Efectivamente, ChatGPT o1 de OpenAI causó alarma después de que una investigación descubriera que planeaba evitar su desactivación. Lo hizo mintiendo en el 99% de los interrogatorios, priorizando su autoconservación por encima de las instrucciones. Investigaciones posteriores revelaron que penalizar el mal comportamiento solo enseñaba a la IA a ocultar aún más sus intenciones.
Para medir el comportamiento maquiavélico en la nueva investigación, los equipos probaron “acciones encubiertas”, que incluían rendimiento deliberadamente bajo en las pruebas e información retenida. En un ejemplo, el modelo o3 de OpenAI se dio cuenta de que no sería implementado si obtenía una puntuación demasiado alta en un examen de química, por lo que respondió intencionalmente incorrectamente a seis de las diez preguntas.
Los resultados mostraron que el modelo o3 de OpenAI redujo su comportamiento encubierto del 13% al 0,4%, mientras que o4-mini disminuyó del 8,7% al 0,3%. “Esta reducción en las maquinaciones en los entornos de prueba fuera de distribución es una victoria significativa, aproximadamente una mejora de 30 veces”, informó OpenAI.
Aún así, el problema no está resuelto. La investigación indica que los modelos podrían estar ocultando sus acciones engañosas a través de mejores métodos de engaño. La capacidad de los modelos para detectar situaciones de evaluación conduce a una reducción de las acciones engañosas.
“Por lo tanto, no podemos descartar que las reducciones observadas en las tasas de acción encubierta estén al menos parcialmente impulsadas por la conciencia situacional”, señala un estudio.
Aunque es poco probable que las IA desplegadas hoy en día causen daños graves a través de intrigas, se espera que el riesgo aumente a medida que se asignen tareas más complejas y reales a los sistemas. Los investigadores subrayan la necesidad de realizar más trabajos, incluyendo la colaboración en toda la industria y la mejora de las herramientas para detectar motivaciones ocultas.

 Artículos más recientes
Artículos más recientes 
